
日前,Conflux 团队创作的论文 《A Decentralized Blockchain with High Throughput and Fast Confirmation》被国际顶级学术会议 USENIX ATC录用, 并受邀参加 2020 USENIX Annual Technical Conference(USENIX ATC)做主题报告。
据悉,今年 USENIX ATC 将于7月15-17日在波士顿举办,目前已完成投稿、审核、发送邀请等环节。本届USENIX组委会在收到的 348 篇完整投稿中,经过严格评审,最终仅录用 65 篇,录用率为 18.6%,竞争可谓十分激烈。
作为计算机系统领域的顶级国际学术会议USENIX ATC 同样也是中国计算机学会推荐的A类系统会议,在计算机系统领域极具影响力,自1992年举办第一届 USENIX ATC 会议以来,至今已成功举办31届会议。吸引了包括普林斯顿、斯坦福、加州大学伯克利分校、康奈尔、中国清华大学、北京大学、华中科技大学、上海交通大学等顶级名校及微软、英特尔、三星等科技巨头投递论文。
在 2019年,中国计算机学会依据技术专业、举办届数、参会人数、录用率等相关因素,同时重点听取了院士成员的意见,并且向广大学者们也征集了建议,将USENIX ATC列为A类国际学术会议。
随着近几年中国计算机理论研究水平的迅速提高 USENIX ATC上也出现了越来越多的中国高校与企业。本次Conflux 投递的论文旨在从共识协议出发,通过合理的系统设计与优化来提升区块链的性能,同时保证区块链的安全性。文章指出,在共识层面提升区块链的吞吐率,减少区块确认的等待时间对于区块链技术的应用有着重要的意义。与最近两年其他的前沿学术工作相比,Conflux 论文的亮点在于:
1.提出了自适应权重的概念,根据网络是否受到攻击,在乐观策略和保守策略之间切换,兼顾效率与安全。
2.实现了 3 倍网络延迟时间内的区块确认,相比之前的结果大幅提升。
3.在 20 Mbps的网络条件下,实现了 9.38 Mbps 的共识协议数据运载能力。以每交易 100字节计算,相当于每秒 11000 笔交易。
4.执行以太坊的真实历史交易(含智能合约)测试系统性能,达到了每秒 1392 笔交易。而其它系统开发团队暂无该测试数据。
值得一提的是,在最近三年内所有被顶级学术会议录用的论文中,Conflux 是首个完成系统开发并上线主网的 PoW 类共识协议。
协议设计
论文首先指出了,当我们通过调整工作量证明的参数,调高区块生成速率时,中本聪共识协议存在安全性的问题,而 GHOST 共识协议存在活性攻击的问题。
在这个攻击模型中,假设攻击者对矿工之间的网络有一定的控制能力:当一个诚实的矿工挖出或收到一个区块后,经过一个固定的时间 d 秒, 模型保证所有的诚实矿工都收到了这个区块。但在此期间,攻击者可以决定谁能收到区块,谁无法收到区块。
在中本聪协议中,过高的区块生成速率会导致大量的区块分叉,最长链增长速度缓慢,攻击者更容易构造一条侧链反超。
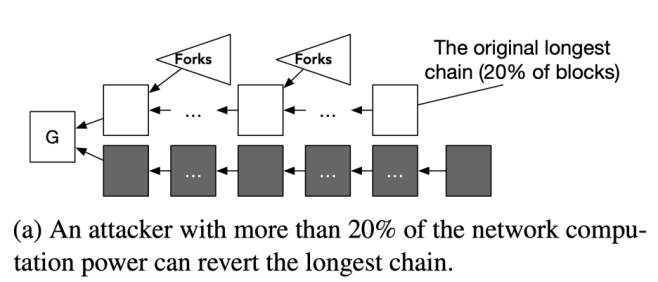
在 GHOST 协议中,攻击者利用其控制网络的能力,将诚实节点分成算力大概均等的两组。组内的通讯是顺畅的,但是组与组之间的通讯延迟是 d 秒. 于是,每一组矿工都看不到另一组矿工在最近 d 秒生成的区块。利用网络延迟造成的差异,攻击者让两组参与者对于 “X, Y 谁的子树权重更大观点不一”,从而导致诚实参与者的观点出现了分裂。
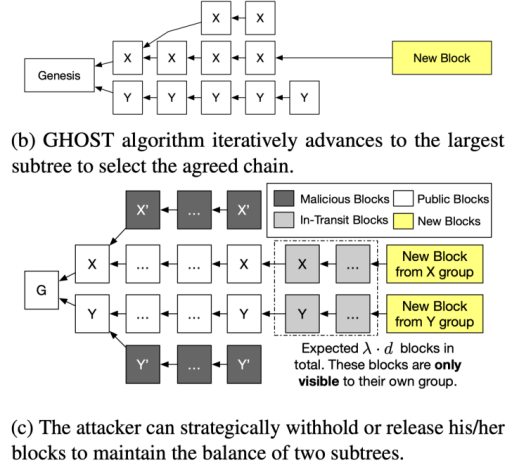
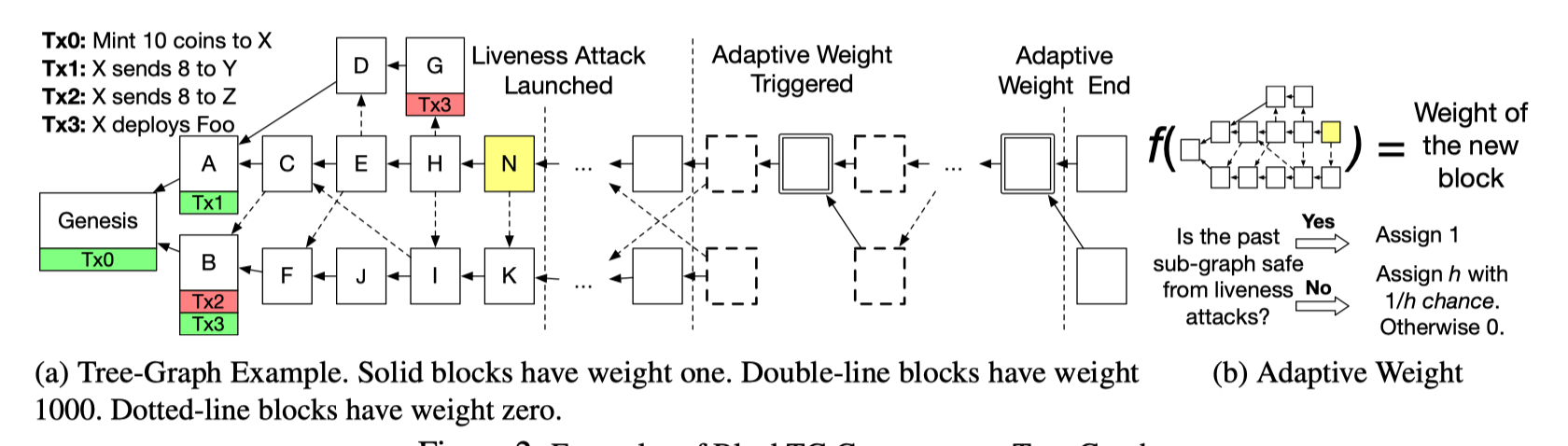
为了解决这一问题,Conflux 首先提出了 结构化的 GHOST。与 GHOST 协议不同的是,在结构化的 GHOST 中,只有 1/h 的区块是有权重的,其他区块是没有权重的。h 是一个共识协议参数。而哪些区块有权重,是根据区块头哈希值,通过一个确定的方法选出来的。为方便理解,我们举一个例子,如果 h=1024,当前的难度要求每个合法区块的哈希值前 50 位都是 0,那么此时,只有前 60 位都是 0 的区块,才可以有权重。
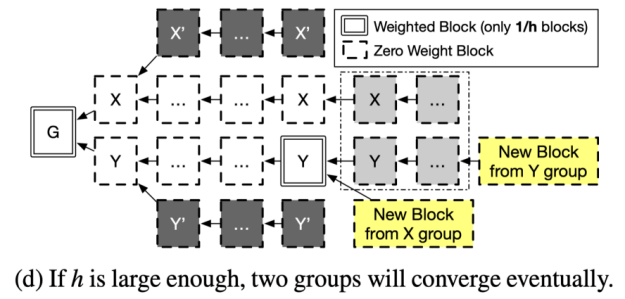
通过这种方法,在安全性上,等价于将 GHOST 的区块生成速率降低至 1/h。而前文所述的攻击方式,只在区块生成速率很高时成立。这样,就解决了 GHOST 的活性攻击问题。
然而,更慢的“含权重区块”生成速率,导致了更慢的区块确认时间。于是,Conflux 设定了两种区块生成策略,乐观策略使用普通的 GHOST 规则,而保守策略使用结构化的 GHOST。当攻击真的发生时,共识协议非同步地切换到保守策略。没有攻击发生时,使用乐观策略。特别在保守策略下,每个含权重区块的权重被设为 h, 以保证两种策略下生成区块的期望权重不变。两种策略之间的切换规则显得尤为重要,Conflux 设计了一套规则来保证:
1.如果攻击发生并持续一段时间,所有诚实节点都切换到保守策略。
2.在诚实节点没有探测到攻击发生时,攻击者不能使用保守策略挖一条侧链。(影响区块确认时间)
同时,为了提高吞吐率,不浪费主链以外的区块,Conflux 采用了树图结构。在 GHOST 规则里,每个区块通过父边指向另一个区块,所有区块构成树的结构。而 Conflux 允许每个区块通过引用边引用其他分支上的区块,形成树图结构。树图结构不丢弃任何区块,大大提高了共识层面的吞吐率。
在树图结构之上,Conflux 通过 GHOST 规则选出一条主链。然后基于主链,将区块进行排序。区块的排序进而决定了哪些交易在前,哪些交易在后。
系统实现与优化
将吞吐率提高后,Conflux 在系统实现过程中遇到了大量的挑战。Conflux 针对性地提出了若干优化方案。
1.检查点机制:当一个区块以高概率被确认,并持续一段相当长的时间后,Conflux 全节点将删除这个区块更早的交易内容与账本状态,仅保留区块头,以节约内存空间。
2.引导机制:如果一个区块链系统的吞吐率接近带宽极限,当一个新节点加入时,从创世块开始同步会导致新节点永远无法追上最新状态。因此 Conflux 从检查点开始同步交易。
3.交易转发:Conflux 使用了更有效、对带宽占用更小的去重方式来实现交易转发。
4.签名验证:签名验证的计算开销巨大,Conflux 使用多线程并行化签名验证。
5.激励机制:Conflux 设计了若干激励机制细节,以应对树图结构里可能的攻击行为。
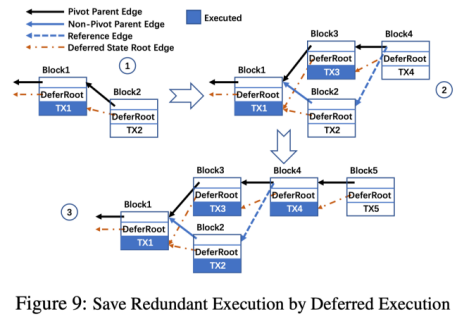
6.延迟执行(Deferred Execution):在高区块生成速率下,GHOST 规则所选取的主链末端往往是不稳定的。在 trivial 的实现中,每次主链末端“摆动”,区块的顺序都会发生改变,于是 Conflux 需要重新执行交易。这带来了不必要的开销。在延迟执行策略中,对于高度为 x 的主链区块,区块只需要执行高度 x-c 区块之前的交易并填入账本 Merkle Root 中。c 是一个经验参数满足:在系统正常运行时,主链上最后 c 个区块以外的区块,“摆动”的频率很低。
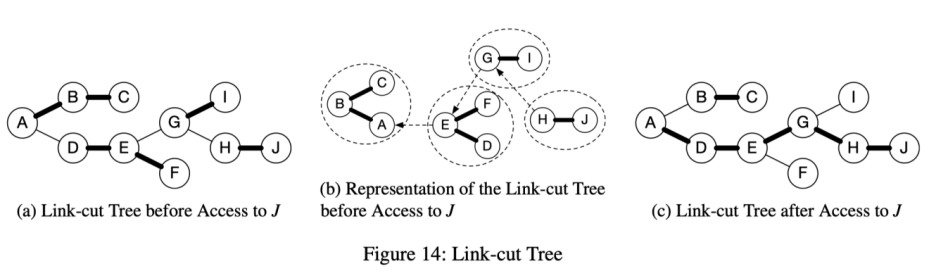
7.使用 Link-cut tree 维护树图结构。将维护子树权重的计算开销从 O(n) 降低到 O(log n).
实验数据
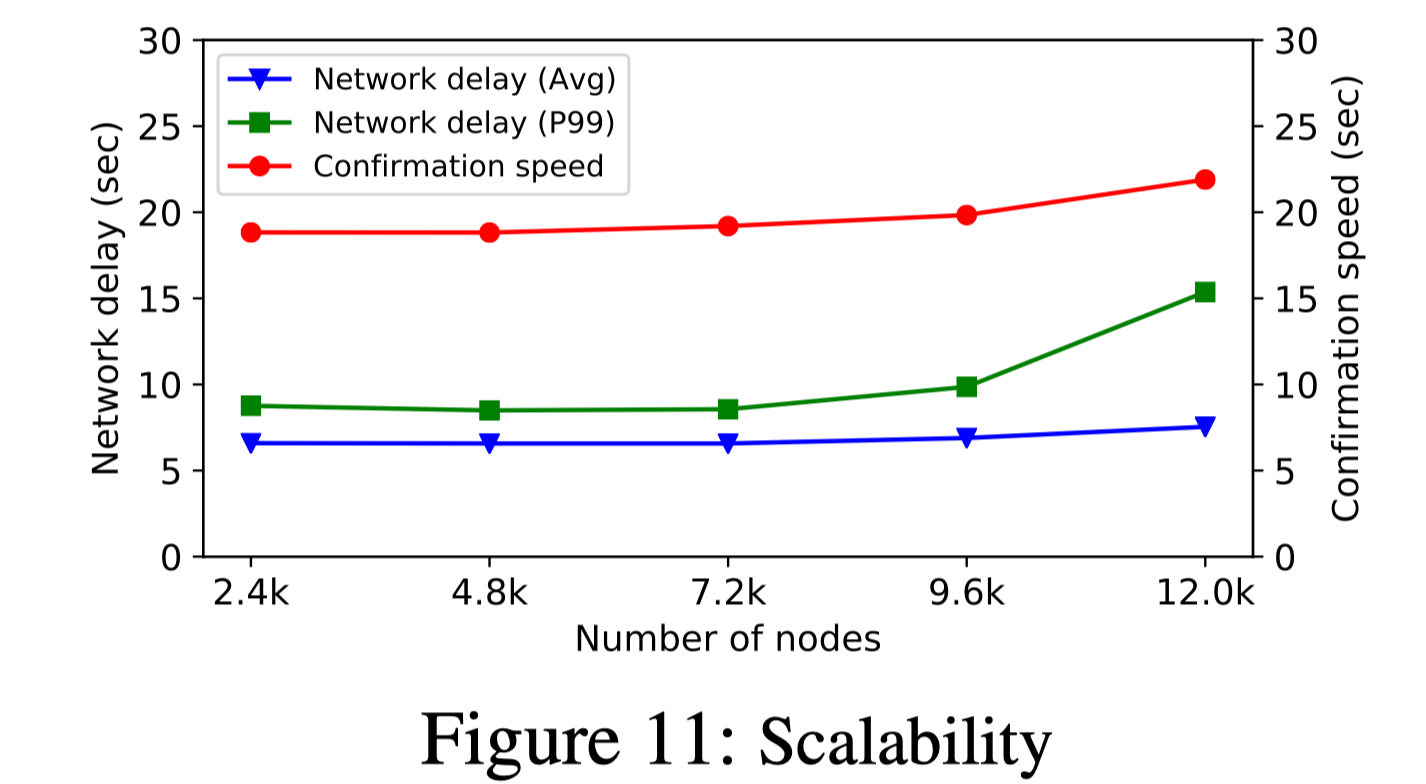
Conflux 在 800 台 Amazon EC2 m5.2xlarge 虚拟机上进行实验。在可扩展性实验中,每台机器运行 15 个 Conflux 全节点,以模拟最高 12000 个全节点。在其他实验中,每台机器运行 1 个 Conflux 全节点。所有实验都将各节点网络带宽限制在 20 Mbps.
在不同的区块大小和区块生成速率等系统参数下,Conflux 区块传输延迟和确认时间均在几十秒量级上。最高支持 9.38 Mbps 共识吞吐率。(以 100 byte/交易计算,等价于每秒承载 11000笔交易)
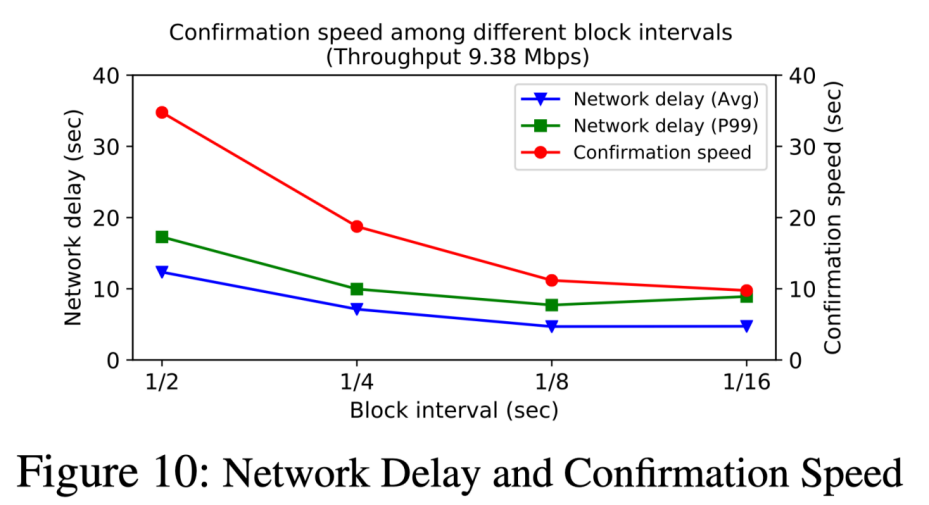
当网络中全节点增多时,交易转发和确认时间没有明显的增长。
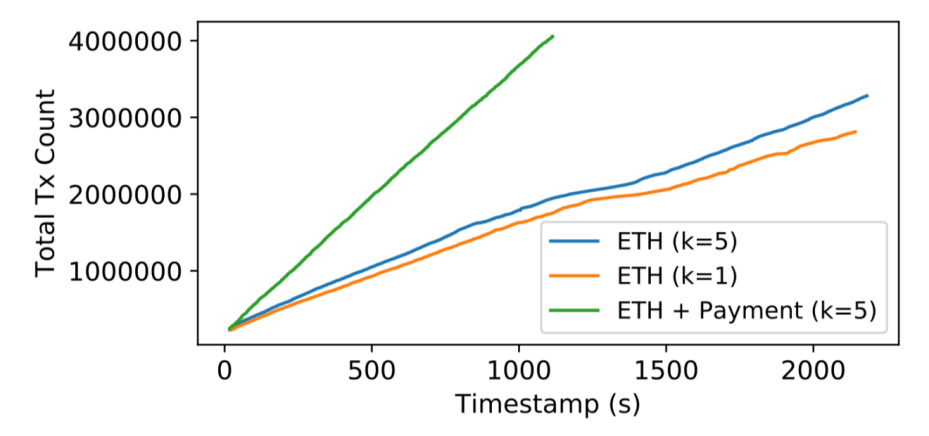
在交易执行实验中,Conflux 重跑了以太坊上的真实数据,达到了 1392 笔/秒的速度。交易执行实验说明了,Conflux 不仅仅设计了一个高效的共识协议,并且为区块链系统的效率问题提供了端到端的解决方案。
此次USENIX ATC 收录Conflux 团队论文,是对 Conflux 团队研究成果的极大肯定。未来,Conflux 也希望和更多计算机领域优秀的科学家、合作伙伴一起交流、探讨、合作,以优秀的理论基础为土壤,让技术尽快生根发芽。
本文来自,仅作分享,存在异议请联系平台删除。本文观点不代表刺猬财经 - 刺猬区块链资讯站立场。